Mọi điều bạn cần biết về Context Engineering để triển khai các ứng dụng AI thành công
Hãy làm rõ một điều: nếu bạn vẫn chỉ nói về “prompt engineering,” bạn đã đi sau thời đại. Trong những ngày đầu của các Mô hình ngôn ngữ lớn (LLM), việc tạo ra một prompt hoàn hảo là cốt lõi của mọi việc.
Đối với các chatbot đơn giản vào năm 2022, điều đó là đủ. Sau đó, Retrieval-Augmented Generation (RAG) xuất hiện vào năm 2023, khi chúng ta bắt đầu cung cấp cho các mô hình kiến thức chuyên sâu theo từng lĩnh vực. Giờ đây, chúng ta có các agent có khả năng sử dụng công cụ, có bộ nhớ, cần xây dựng mối quan hệ và duy trì trạng thái theo thời gian. Sự tập trung vào một tương tác duy nhất của prompt engineering không còn hiệu quả nữa.

Khi các ứng dụng AI trở nên phức tạp hơn, việc chỉ đơn giản đưa thêm thông tin vào prompt sẽ dẫn đến những vấn đề nghiêm trọng. Thứ nhất, đó là context decay (suy giảm ngữ cảnh). Các mô hình bị bối rối bởi các ngữ cảnh dài, lộn xộn, dẫn đến hallucination (ảo giác) và câu trả lời sai lệch. Một nghiên cứu gần đây cho thấy độ chính xác của mô hình có thể bắt đầu giảm đáng kể khi ngữ cảnh vượt quá 32.000 token, rất lâu trước khi đạt đến giới hạn 2 triệu token được quảng cáo [1].
Thứ hai, context window (cửa sổ ngữ cảnh) — bộ nhớ làm việc của mô hình — là hữu hạn. Ngay cả với các cửa sổ lớn, mỗi token đều làm tăng chi phí và độ trễ. Tôi đã từng xây dựng một quy trình làm việc mà tôi nhồi nhét mọi thứ vào ngữ cảnh: nghiên cứu, hướng dẫn, ví dụ và đánh giá. Kết quả là thời gian chạy lên đến 30 phút. Nó hoàn toàn không thể sử dụng được. Cách tiếp cận ngây thơ của “tạo sinh tăng cường ngữ cảnh” (context-augmented generation), hay chỉ đơn giản là đổ tất cả mọi thứ vào, là một công thức dẫn đến thất bại khi triển khai sản phẩm.
Đây chính là lúc context engineering phát huy tác dụng. Đó là sự thay đổi tư duy, từ việc chỉ soạn thảo các prompt riêng lẻ sang việc xây dựng toàn bộ hệ sinh thái thông tin cho AI. Chúng ta chủ động thu thập và lọc thông tin từ bộ nhớ, cơ sở dữ liệu và các công cụ khác để cung cấp cho LLM chính xác những gì cần thiết cho một nhiệm vụ cụ thể. Điều này giúp hệ thống của chúng ta chính xác hơn, nhanh hơn và tiết kiệm chi phí hơn.
Hiểu về Context Engineering
Vậy, context engineering chính xác là gì? Câu trả lời chính thức là nó là một bài toán tối ưu hóa: tìm ra tập hợp các hàm lý tưởng để xây dựng một ngữ cảnh có thể tối đa hóa chất lượng đầu ra của LLM cho một nhiệm vụ nhất định [2].
Nói một cách đơn giản, context engineering là việc sắp xếp một cách có chiến lược để lấp đầy context window (cửa sổ ngữ cảnh) hạn chế của mô hình với thông tin phù hợp, vào đúng thời điểm và ở đúng định dạng. Chúng ta trích xuất những mảnh ghép cần thiết từ cả bộ nhớ ngắn hạn và dài hạn để giải quyết một nhiệm vụ mà không làm mô hình bị quá tải.
Andrej Karpathy đã đưa ra một phép so sánh tuyệt vời: LLM giống như một loại hệ điều hành mới, trong đó mô hình đóng vai trò là CPU và context window của nó hoạt động như RAM [3]. Giống như một hệ điều hành quản lý những gì được đưa vào RAM, context engineering quản lý những gì chiếm giữ bộ nhớ làm việc của mô hình. Điều quan trọng cần lưu ý là ngữ cảnh là một tập con của tổng bộ nhớ làm việc của hệ thống; bạn có thể lưu trữ thông tin mà không cần truyền nó cho LLM trong mỗi lượt tương tác.
Ngành học mới này về cơ bản khác với việc chỉ viết các prompt tốt. Để tạo ra ngữ cảnh một cách hiệu quả, trước tiên bạn cần hiểu những thành phần nào bạn thực sự có thể thao tác.
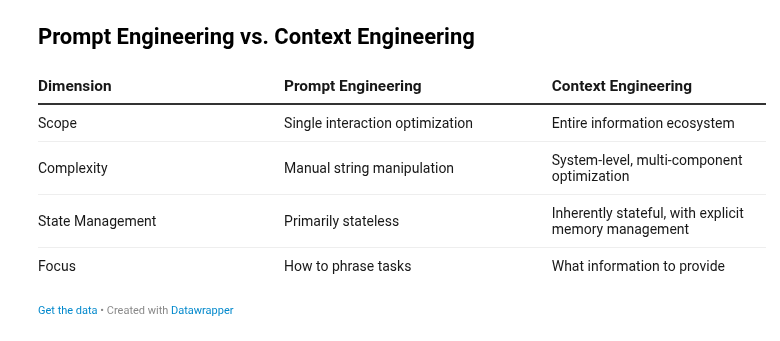
Context engineering không thay thế prompt engineering. Thay vào đó, bạn có thể hiểu một cách trực quan prompt engineering là một phần của context engineering. Bạn vẫn cần học cách viết prompt tốt trong khi thu thập đúng ngữ cảnh và đưa chúng vào prompt mà không làm hỏng LLM. Đó chính là tất cả những gì context engineering hướng đến! Chi tiết hơn trong bảng dưới đây.
So sánh: Prompt Engineering và Context Engineering
Các thành phần tạo nên Ngữ cảnh
Ngữ cảnh chúng ta truyền cho một LLM không phải là một chuỗi tĩnh; chúng ta tập hợp dữ liệu này một cách linh hoạt (dynamically) cho mỗi và mọi tương tác. Nhiều hệ thống bộ nhớ khác nhau tạo nên dữ liệu này, mỗi hệ thống phục vụ một mục đích riêng biệt, được lấy cảm hứng từ khoa học nhận thức [4].
Dưới đây là các thành phần cốt lõi tạo nên ngữ cảnh của LLM:
- System Prompt: Chứa các hướng dẫn cốt lõi, quy tắc và tính cách của agent. Hãy nghĩ nó như bộ nhớ thủ tục (procedural memory) của agent, xác định cách nó nên hành xử.
- Message History: Đây là phần đối thoại qua lại gần nhất, bao gồm cả đầu vào của người dùng và độc thoại nội tâm của agent (suy nghĩ, hành động và quan sát từ việc sử dụng công cụ). Đây đóng vai trò như bộ nhớ làm việc ngắn hạn (short-term working memory) của agent.
- User Preferences and Past Experiences: Đây là bộ nhớ kinh nghiệm (episodic memory) của agent, lưu trữ các sự kiện cụ thể và các dữ kiện liên quan đến người dùng, thường trong cơ sở dữ liệu vector hoặc đồ thị. Nó cho phép cá nhân hóa, chẳng hạn như ghi nhớ vai trò của bạn hoặc các yêu cầu trước đây [5].
- Retrieved Information: Đây là bộ nhớ ngữ nghĩa (semantic memory) — kiến thức thực tế được lấy từ các cơ sở kiến thức nội bộ (như tài liệu hoặc hồ sơ công ty) hoặc các nguồn bên ngoài thông qua các lời gọi API theo thời gian thực. Đây là cốt lõi của RAG.
- Tool and Structured Output Schemas: Đây cũng là một dạng bộ nhớ thủ tục, xác định các công cụ mà agent có thể sử dụng và định dạng mà nó nên dùng cho phản hồi của mình.
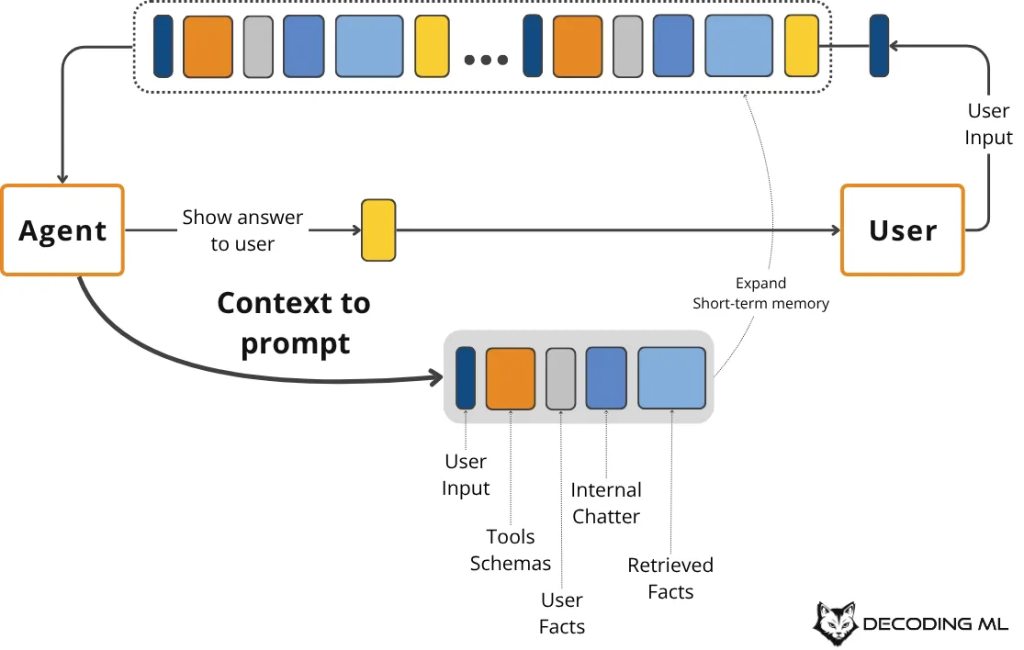
Luồng làm việc này mang tính chu kỳ và linh hoạt. Một truy vấn hoặc nhiệm vụ của người dùng sẽ kích hoạt việc truy xuất thông tin từ các nguồn bộ nhớ dài hạn (kinh nghiệm, ngữ nghĩa, thủ tục). Quá trình này được gọi là thành phần agentic RAG của hệ thống.
Tiếp theo, chúng ta kết hợp thông tin này với bộ nhớ làm việc ngắn hạn, tool schemas và structured output schemas để tạo ra ngữ cảnh cuối cùng cho lời gọi LLM. Phản hồi của LLM sẽ cập nhật bộ nhớ làm việc, và chúng ta có thể ghi lại những hiểu biết quan trọng vào bộ nhớ dài hạn, tinh chỉnh hệ thống cho các tương tác trong tương lai.
Những thách thức khi triển khai sản phẩm
Xây dựng một quy trình context engineering mạnh mẽ không hề đơn giản. Trong môi trường sản xuất, bạn sẽ gặp phải một số vấn đề nan giải có thể làm giảm hiệu suất của agent nếu không được quản lý đúng cách.
Đầu tiên là thách thức về cửa sổ ngữ cảnh (context window). Ngay cả với các context window khổng lồ, không gian này vẫn là một tài nguyên hữu hạn và tốn kém. Cơ chế self-attention, cốt lõi của LLM, gây ra chi phí tính toán và bộ nhớ bậc hai [2]. Mỗi token đều làm tăng chi phí và độ trễ, nhanh chóng lấp đầy context window với lịch sử trò chuyện, đầu ra của công cụ và các tài liệu đã truy xuất, tạo ra một giới hạn cứng về những gì agent có thể “nhìn thấy”.
Điều này dẫn đến quá tải thông tin (information overload), còn được gọi là suy giảm ngữ cảnh (context decay) hoặc vấn đề “mất-ở-giữa” (lost-in-the-middle). Các nghiên cứu cho thấy khi bạn nhồi nhét càng nhiều thông tin vào ngữ cảnh, các mô hình càng mất khả năng tập trung vào các chi tiết quan trọng [1]. Hiệu suất thường giảm đột ngột, dẫn đến các phản hồi mơ hồ hoặc không liên quan. Việc mất thông tin này cũng có thể kích hoạt hallucination (ảo giác), khi các mô hình cố gắng điền vào những khoảng trống nhận thấy [6].
Một vấn đề tinh tế khác là trôi dạt ngữ cảnh (context drift), nơi các phiên bản mâu thuẫn của sự thật tích lũy theo thời gian. Ví dụ, nếu bộ nhớ chứa cả thông tin “Ngân sách của người dùng là $500” và sau đó là “Ngân sách của người dùng là $1.000,” agent có thể bị bối rối. Nếu không có cơ chế để giải quyết hoặc loại bỏ các dữ kiện lỗi thời, cơ sở kiến thức của agent sẽ trở nên không đáng tin cậy.
Cuối cùng, có vấn đề nhầm lẫn công cụ (tool confusion). Chúng ta thường thấy sự thất bại khi cung cấp cho một agent quá nhiều công cụ, đặc biệt với các mô tả kém hoặc chức năng chồng chéo. Gorilla benchmark cho thấy gần như tất cả các mô hình hoạt động kém hơn khi được cung cấp nhiều hơn một công cụ [7]. Agent bị tê liệt vì quá nhiều lựa chọn hoặc chọn sai công cụ, dẫn đến thất
Các chiến lược tối ưu hóa ngữ cảnh quan trọng
Thời gian đầu, hầu hết các ứng dụng AI chỉ là những hệ thống RAG đơn giản. Ngày nay, các agent xử lý cùng lúc nhiều nguồn dữ liệu, công cụ và loại bộ nhớ, đòi hỏi một cách tiếp cận tinh vi hơn đối với context engineering. Dưới đây là các chiến lược chính để quản lý context window của LLM một cách hiệu quả.
Lựa chọn ngữ cảnh phù hợp
Việc lựa chọn ngữ cảnh phù hợp là tuyến phòng thủ đầu tiên của bạn. Tránh cung cấp tất cả ngữ cảnh có sẵn; thay vào đó, hãy sử dụng RAG với reranking để chỉ truy xuất những dữ kiện liên quan nhất.
Structured outputs cũng có thể đảm bảo LLM chia các phản hồi thành các phần logic, chỉ chuyển những phần cần thiết xuống luồng tiếp theo. Việc tối ưu hóa ngữ cảnh động này sẽ lọc nội dung và chọn lọc thông tin quan trọng để tối đa hóa mật độ trong context window giới hạn [2].
Nén ngữ cảnh
Context compression (nén ngữ cảnh) rất quan trọng để quản lý các cuộc hội thoại dài. Khi lịch sử tin nhắn tăng lên, hãy tóm tắt hoặc cô đọng nó để tránh làm tràn context window, giống như cách bạn quản lý RAM của máy tính.
Bạn có thể sử dụng LLM để tạo bản tóm tắt các lượt hội thoại cũ, di chuyển các dữ kiện quan trọng vào bộ nhớ kinh nghiệm dài hạn bằng các công cụ như mem0, hoặc sử dụng kỹ thuật loại bỏ trùng lặp bằng MinHash [8].
Sắp xếp ngữ cảnh
Các LLM thường chú ý nhiều hơn đến phần đầu và cuối của một prompt, thường làm mất thông tin ở giữa — hiện tượng “mất-ở-giữa” (lost-in-the-middle) [1].
Hãy đặt các hướng dẫn quan trọng ở đầu và dữ liệu gần nhất hoặc liên quan nhất ở cuối.
Reranking và temporal relevance đảm bảo các LLM không chôn vùi thông tin quan trọng [2]. Ưu tiên ngữ cảnh động cũng có thể giải quyết các mơ hồ và duy trì các phản hồi được cá nhân hóa bằng cách thích ứng với sở thích ngày càng thay đổi của người dùng [9].
Phân lập ngữ cảnh
Isolating context (phân lập ngữ cảnh) bao gồm việc phân chia một vấn đề phức tạp cho nhiều agent chuyên biệt. Mỗi agent sẽ duy trì context window tập trung của riêng mình, ngăn ngừa sự can thiệp và cải thiện hiệu suất.
Đây là một nguyên tắc cốt lõi đằng sau các hệ thống multi-agent, tận dụng nguyên tắc “tách biệt mối quan tâm” (separation of concerns) cũ mà hiệu quả từ kỹ thuật phần mềm.
Tối ưu hóa định dạng
Cuối cùng, việc tối ưu hóa định dạng bằng cách sử dụng các cấu trúc như XML hoặc YAML giúp mô hình tiêu hóa ngữ cảnh dễ dàng hơn. Điều này phân định rõ ràng các loại thông tin khác nhau và cải thiện độ tin cậy của quá trình suy luận.
💡 Mẹo: Luôn sử dụng YAML thay vì JSON, vì nó tiết kiệm token

Một ví dụ cụ thể
Context engineering không chỉ là một khái niệm lý thuyết; chúng ta áp dụng nó để xây dựng các hệ thống AI mạnh mẽ trong nhiều lĩnh vực khác nhau.
- Trong y tế, một trợ lý AI có thể truy cập lịch sử bệnh án, triệu chứng hiện tại và các tài liệu y khoa liên quan của bệnh nhân để đưa ra các chẩn đoán được cá nhân hóa.
- Trong tài chính, một agent có thể tích hợp với hệ thống Customer Relationship Management (CRM) của công ty, lịch làm việc và dữ liệu tài chính để đưa ra quyết định dựa trên sở thích của người dùng.
- Trong quản lý dự án, một hệ thống AI có thể truy cập các công cụ doanh nghiệp như CRM, Slack, Zoom, lịch và trình quản lý tác vụ để tự động hiểu các yêu cầu của dự án và cập nhật các tác vụ.
Hãy cùng xem xét một ví dụ cụ thể. Hãy tưởng tượng một người dùng hỏi một trợ lý y tế: Tôi bị đau đầu. Tôi có thể làm gì để hết đau? Tôi không muốn uống thuốc.
Ngay cả trước khi LLM nhìn thấy truy vấn này, một hệ thống context engineering đã bắt đầu hoạt động:
- Hệ thống truy xuất lịch sử bệnh án, các dị ứng đã biết và thói quen sinh hoạt của người dùng từ một kho bộ nhớ kinh nghiệm (episodic memory), thường là một cơ sở dữ liệu vector hoặc đồ thị [5].
- Hệ thống truy vấn một bộ nhớ ngữ nghĩa (semantic memory) chứa các tài liệu y khoa cập nhật để tìm các biện pháp không dùng thuốc cho chứng đau đầu [4].
- Hệ thống tập hợp thông tin này, cùng với truy vấn của người dùng và lịch sử cuộc trò chuyện, vào một prompt có cấu trúc.
- Chúng ta gửi prompt đến LLM, và nó tạo ra một khuyến nghị được cá nhân hóa, an toàn và phù hợp.
- Chúng ta ghi lại tương tác và lưu bất kỳ sở thích mới nào trở lại bộ nhớ kinh nghiệm của người dùng.
Dưới đây là một ví dụ Python đơn giản cho thấy cách các thành phần này có thể được tập hợp thành một system prompt hoàn chỉnh. Hãy chú ý đến cấu trúc và thứ tự rõ ràng.
Ví dụ System Prompt cho trợ lý AI y tế:
Python
SYSTEM_PROMPT = """
Bạn là một trợ lý y tế AI hữu ích và thận trọng. Mục tiêu của bạn là cung cấp lời khuyên an toàn, không dùng thuốc. Không đưa ra chẩn đoán y tế.
<INSTRUCTIONS>
1. Phân tích truy vấn của người dùng và ngữ cảnh được cung cấp.
2. Sử dụng lịch sử bệnh án để hiểu hồ sơ sức khỏe và sở thích của họ.
3. Sử dụng kiến thức y tế đã truy xuất để đưa ra khuyến nghị của bạn.
4. Nếu bạn thiếu thông tin, hãy hỏi các câu hỏi làm rõ.
5. Luôn ưu tiên sự an toàn và khuyên người dùng nên tham khảo ý kiến bác sĩ đối với các vấn đề nghiêm trọng.
</INSTRUCTIONS>
<PATIENT_HISTORY>
{retrieved_patient_history}
</PATIENT_HISTORY>
<MEDICAL_KNOWLEDGE>
{retrieved_medical_articles}
</MEDICAL_KNOWLEDGE>
<CONVERSATION_HISTORY>
{formatted_chat_history}
</CONVERSATION_HISTORY>
<USER_QUERY>
{user_query}
</USER_QUERY>
Dựa trên tất cả các thông tin trên, hãy cung cấp một phản hồi hữu ích.
"""
Tuy nhiên, mấu chốt vẫn nằm ở hệ thống xung quanh nó, vốn có nhiệm vụ cung cấp ngữ cảnh thích hợp để điền vào system prompt.
Để xây dựng một hệ thống như vậy, bạn sẽ sử dụng sự kết hợp của nhiều công cụ. Một LLM như Gemini cung cấp công cụ suy luận. Một framework như LangChain điều phối luồng làm việc. Các cơ sở dữ liệu như PostgreSQL, Qdrant, hoặc Neo4j đóng vai trò là kho lưu trữ bộ nhớ dài hạn. Các công cụ chuyên biệt như Mem0 có thể quản lý trạng thái bộ nhớ, và các nền tảng quan sát (observability platforms) là rất cần thiết để gỡ lỗi các tương tác phức tạp.
Kết nối Context Engineering với AI Engineering
Nắm vững context engineering ít liên quan đến việc học một thuật toán cụ thể mà chủ yếu là xây dựng trực giác. Đó là nghệ thuật biết cách cấu trúc prompt, nên đưa những thông tin gì vào, và sắp xếp chúng như thế nào để đạt hiệu quả tối đa.
Kỹ năng này không tồn tại trong chân không. Đó là một lĩnh vực đa ngành, nằm ở giao điểm của một số lĩnh vực kỹ thuật chính:
- AI Engineering: Hiểu về LLM, RAG, và AI agent là nền tảng.
- Software Engineering: Bạn cần xây dựng các hệ thống có khả năng mở rộng và dễ bảo trì để tổng hợp ngữ cảnh và đóng gói các agent trong các API mạnh mẽ.
- Data Engineering: Xây dựng các data pipelines đáng tin cậy cho RAG và các hệ thống bộ nhớ khác là rất quan trọng.
- MLOps: Triển khai các agent trên cơ sở hạ tầng phù hợp và tự động hóa Continuous Integration/Continuous Deployment (CI/CD) giúp chúng có thể tái tạo, quan sát được và có khả năng mở rộng.
Cách tốt nhất để phát triển kỹ năng context engineering của bạn là thực hành.
Hãy bắt đầu xây dựng các AI agent tích hợp RAG cho bộ nhớ ngữ nghĩa, các công cụ cho bộ nhớ thủ tục, và hồ sơ người dùng cho bộ nhớ kinh nghiệm. Khi bạn vật lộn với những đánh đổi của việc quản lý ngữ cảnh trong một dự án thực tế, bạn sẽ xây dựng được trực giác, thứ phân biệt một chatbot đơn giản với một agent thực sự thông minh.
Bây giờ, hãy ngừng đọc và xây dựng ứng dụng AI tiếp theo của bạn bằng cách sử dụng tất cả các kỹ năng context engineering này!
Hẹn gặp lại bạn vào tuần tới, Paul Iusztin
👋 Tôi rất mong nhận được phản hồi của bạn để giúp cải thiện Decoding ML. Hãy chia sẻ điều bạn muốn thấy tiếp theo hoặc bài học lớn nhất của bạn. Tôi đọc và trả lời mọi bình luận!
Khi bạn đã sẵn sàng, có 3 cách chúng tôi có thể giúp bạn:
- Perks: Giảm giá độc quyền cho các tài liệu học tập được chúng tôi đề xuất (sách, khóa học trực tiếp, khóa học tự học và nền tảng học tập).
- The LLM Engineer’s Handbook: Cuốn sách bán chạy nhất của chúng tôi, hướng dẫn bạn một framework từ đầu đến cuối để xây dựng các ứng dụng LLM và RAG sẵn sàng cho môi trường sản xuất, từ thu thập dữ liệu đến triển khai (giảm tới 20% khi sử dụng mã giảm giá của chúng tôi).
- Free open-source courses: Nắm vững AI sản xuất với các khóa học mã nguồn mở từ đầu đến cuối của chúng tôi, phản ánh các dự án AI thực tế và bao gồm mọi thứ từ kiến trúc hệ thống đến thu thập dữ liệu, đào tạo và triển khai.
Tài liệu tham khảo:
[1] Long-context RAG performance on LLMs
[2] A Survey of Context Engineering for Large Language Models
[3] Andrej Karpathy on Context Engineering
[5] AI agent memory
[6] LLM-based Generation of E-commerce Product Descriptions
[9] Dynamic Context Prioritization for Personalized Response Generation
[10] Building a multi-agent research system
[11] AI Agent Architecture Patterns
[12] The 12-Factor Agent: Own Your Context Window
Nguồn: decodingml.substack.com






0 Lời bình