
Sau nhiều tháng rục rịch, Google bắt đầu triển khai mô hình trí tuệ nhân tạo Generative AI, Gemini.
Mô hình mới, sẽ được ra mắt theo từng giai đoạn, là cơ hội của Google để ngăn chặn câu chuyện rằng họ đã tụt lại so với đối thủ như OpenAI.
Trong khi người dùng sẽ có thể truy cập vào Gemini trong tháng này thì phiên bản tiên tiến nhất của mô hình sẽ không xuất hiện cho đến đầu năm sau.
Gemini có ba phiên bản và sẽ được cung cấp theo từng giai đoạn: Ultra, Pro và Nano. Phiên bản cuối cùng sẽ được thiết kế để chạy trên thiết bị như điện thoại thông minh.
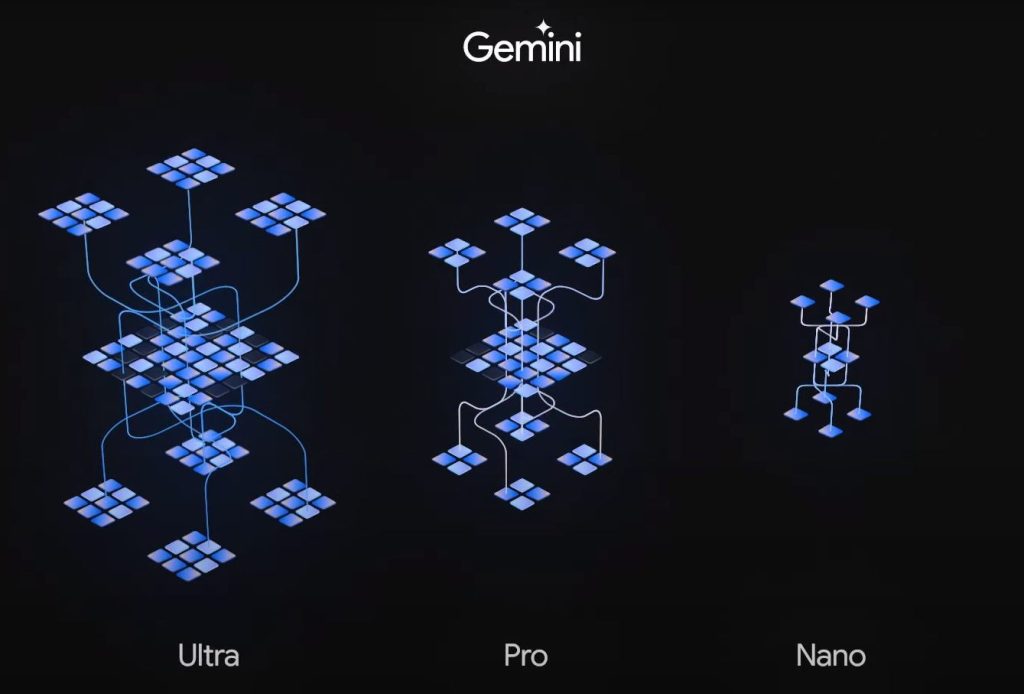
Google sẽ cung cấp phiên bản Pro cho người dùng vào thứ Tư thông qua chatbot Bard, và cung cấp cho khách hàng Cloud trong những ngày sắp tới, nhưng họ cho biết mô hình Ultra – mô hình lớn nhất và kỹ thuật tiên tiến nhất trong ba mô hình – vẫn đang trải qua thử nghiệm nội bộ và sẽ không triển khai cho đến đầu năm 2024.
Google cho biết họ dự định tích hợp Gemini vào các sản phẩm phổ biến nhất của mình theo thời gian. Họ cũng sẽ ra mắt Gemini Ultra cho một phiên bản mới của Bard gọi là Bard Advanced vào năm sau. Sissie Hsiao, Phó Chủ tịch và Quản lý chung của Bard và Assistant của Google, không nói rõ liệu việc sử dụng Bard Advanced có phải trả tiền hay không, nhưng cũng không phủ nhận khả năng này.
Hiện nay, có áp lực lớn đặt lên Google để chứng minh rằng họ vẫn là người dẫn đầu trong ngành công nghiệp trí tuệ nhân tạo với Gemini, một mô hình được huấn luyện đa phương tiện, có nghĩa là nó có thể xử lý nhiều loại dữ liệu như văn bản, hình ảnh, video và âm thanh. Nhưng Google tự hào cho biết Gemini cũng là mô hình “linh hoạt nhất” của họ, có khả năng chạy trên nhiều nguồn từ trung tâm dữ liệu đến điện thoại thông minh.
Trong một cuộc trò chuyện với các phóng viên trong tuần này, các nhà quản lý Google cho biết mô hình Ultra của Gemini là mô hình đầu tiên vượt qua các chuyên gia con người trong MMLU (Massive Multitask Language Understanding), một phép đo kiểm tra trên các chủ đề như toán, lịch sử, luật và đạo đức. Mô hình đạt điểm 90,0%, vượt qua 86,4% của GPT-4 của OpenAI.
Mọi thứ nghe có vẻ tuyệt vời, nhưng chúng ta vẫn chưa thể thử nghiệm hết khả năng của Gemini ngay lúc này. Google cho biết mô hình Pro vượt trội so với GPT-3.5, nguồn động của phiên bản miễn phí của ChatGPT, và người dùng sẽ có thể thử nghiệm phiên bản được fine-tune tốt hơn cho Bard bắt đầu từ thứ Tư (Google nói: bắt đầu bằng tiếng Anh, và trừ UK). Nhưng khi được hỏi về cách Gemini so sánh với GPT-4 tổng thể, các nhà quản lý từ chối bình luận (tuy nhiên, họ đã đánh giá so sánh giữa Gemini Ultra và GPT-4 ở nhiều lĩnh vực khác nhau và công bố kết quả tại đây: https://blog.google/technology/ai/google-gemini-ai/#performance).
Một cách công khai, Google đã từ chối mọi ý kiến cho rằng họ đã vội vàng theo đuổi đối thủ, nhưng bên trong công ty mọi thứ trông rất khác khi họ đã nhanh chóng triển khai Gemini và đưa trí tuệ nhân tạo vào tất cả các sản phẩm chính của mình.
Đầu năm nay, CEO Sundar Pichai đã sáp nhập đơn vị quý giá DeepMind của Alphabet với nhóm trí tuệ nhân tạo nội bộ của mình (Brain) để nhanh chóng làm Gemini. Nhân viên cũng được thông báo rằng Google sẽ giảm lượng nghiên cứu được công bố để giới hạn đối thủ thương mại hóa ý tưởng của họ, theo báo cáo của BI.
Google tin rằng Gemini có ưu thế so với đối thủ ở điểm mà họ gọi là “suy luận tinh tế,” đó là cách mô hình xử lý thông tin phức tạp qua các loại dữ liệu (media) khác nhau.
Trong một bản demo được trình bày cho báo chí, các nghiên cứu viên của DeepMind đã sử dụng Gemini để lục soát hàng trăm nghìn bài nghiên cứu để trích xuất các loại dữ liệu cụ thể. Google cho biết Gemini có khả năng phân biệt giữa các bài nghiên cứu liên quan đến nghiên cứu và những bài không liên quan. Điều thú vị hơn, họ có thể hiển thị Gemini một biểu đồ với dữ liệu cũ và yêu cầu nó tạo ra phiên bản cập nhật, với dữ liệu mới được vẽ.
Mặc dù Gemini có thể xử lý nhiều loại dữ liệu (media) khác nhau, Eli Collins, Phó Chủ tịch Sản phẩm của DeepMind, nói rằng các mô hình Gemini ban đầu sẽ không thể tạo ra hình ảnh và video, nhưng gợi ý rằng điều này sẽ xuất hiện trong các mô hình khác trong tương lai.
Collins thêm vào đó rằng Google đã nhận thấy một số khả năng “độc đáo” trong Gemini có thể mang lại ưu thế so với các mô hình đối thủ, nhưng không giải thích chi tiết những điều đó có thể là gì.
Gemini đã được huấn luyện trên và sử dụng các bộ vi xử lý tensor (TPUs), và Google đang sử dụng triển khai Gemini để thông báo về Cloud TPU v5p mới và một siêu máy tính trí tuệ nhân tạo mới sẽ được sử dụng để cải thiện quá trình đào tạo và triển khai trí tuệ nhân tạo. Thú vị là, Amin Vahdat, Phó Chủ tịch tại Google Cloud AI, nói rằng Gemini sẽ chạy trên cả GPU và TPU trong tương lai, nhưng không đi sâu vào chi tiết hơn.
Google cho biết họ sẽ cung cấp Gemini Pro cho khách hàng doanh nghiệp thông qua chương trình Vertex AI của mình, và cho những nhà phát triển trong AI Studio, vào ngày 13 tháng 12.
Còn đối với các sản phẩm dành cho người tiêu dùng ngoài Bard, Google sẽ ra mắt Gemini Nano trên điện thoại thông minh Pixel 8 Pro vào thứ Tư, điều này sẽ kích hoạt các tính năng như tóm tắt nội dung của các bản ghi âm.
Google cũng cho biết họ dự định thêm Gemini vào SGE, phiên bản tìm kiếm của họ được cung cấp bởi trí tuệ nhân tạo Generative AI, cũng như Chrome, Duet AI và các sản phẩm khác, trong những tháng tới.
Theo businessinsider.com



0 Lời bình