Chọn phương pháp tiếp cận phù hợp?
Khi xây dựng ứng dụng phần mềm sử dụng OpenAI API để tạo nội dung hoặc thực hiện các phiên trò chuyện như AI chatbot, việc tích hợp nội dung độc quyền là việc quan trọng để cung cấp câu trả lời phù hợp. Ngoài kỹ thuật đơn giản về prompt, có hai phương pháp thiết kế để tiếp cận: Xây dựng cơ sở dữ liệu vector của toàn bộ nội dung độc quyền (RAG) và tìm kiếm động thông tin liên quan khi người dùng yêu cầu, hoặc gửi nội dung đến OpenAI để huấn luyện điều chỉnh mô hình (fine-tune). Mỗi phương pháp đều có nhược điểm và ưu điểm riêng, và sự chọn lựa giữa hai phương pháp này cuối cùng phụ thuộc vào các yếu tố như kích thước và độ phức tạp của cơ sở tri thức, quyền riêng tư dữ liệu, ngân sách và độ phức tạp của việc triển khai. Trong bài viết này, chúng tôi so sánh và đối chiếu hai phương pháp để giúp bạn quyết định phương án nào phù hợp nhất với mục tiêu và ưu tiên của bạn.
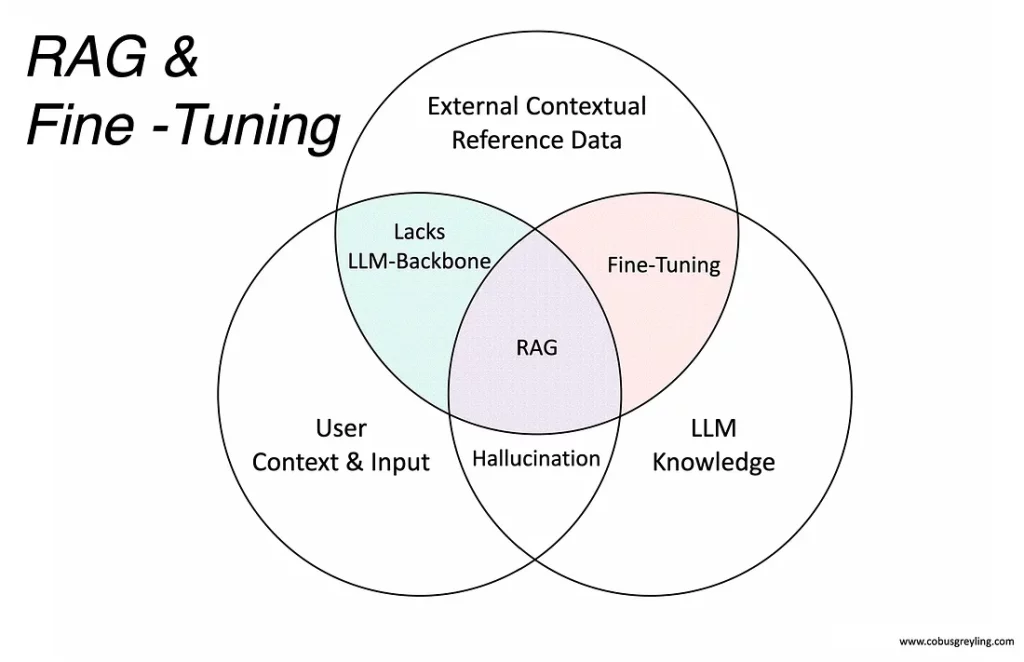
RAG vs Fine-tune
1. Cân nhắc chung
1.1 RAG: Xây dựng cơ sở dữ liệu vector và tìm kiếm động thông tin liên quan
Ưu điểm:
- Kiểm soát dữ liệu: Bạn duy trì hoàn toàn quyền kiểm soát đối với dữ liệu độc quyền của mình, điều này có thể đặc biệt quan trọng đối với thông tin nhạy cảm hoặc mật.
- Linh động: Bạn có thể dễ dàng cập nhật, sửa đổi hoặc mở rộng cơ sở dữ liệu nội dung mà không cần đào tạo lại mô hình.
- Chi phí hiệu quả: Xây dựng cơ sở dữ liệu nhúng và tìm kiếm thông tin liên quan thường ít tốn kém hơn so với việc điều chỉnh mô hình với OpenAI.
- Thời gian phản hồi nhanh: Phát triển cơ sở dữ liệu nhúng và triển khai chức năng tìm kiếm thường nhanh hơn quá trình điều chỉnh tinh chỉnh.
Nhược điểm:
- Phản hồi ít kết hợp: Các phản hồi tạo ra có thể không chặt chẽ hoặc tích hợp tốt như chúng sẽ khi sử dụng một mô hình được điều chỉnh tốt, vì nội dung được kết hợp với đầu vào ban đầu khi chạy.
- Tăng độ phức tạp: Triển khai một cơ chế tìm kiếm hiệu quả và xử lý quá trình truy xuất thông tin tăng độ phức tạp cho phần mềm của bạn.
1.2. Fine-tune: Điều chỉnh mô hình OpenAI
Ưu điểm:
- Tích hợp tốt hơn: Điều chỉnh mô hình với nội dung độc quyền của bạn có thể dẫn đến các phản ứng chặt chẽ hơn, liên quan ngữ cảnh và chính xác hơn.
- Chất lượng tạo ra cải thiện: Một mô hình được điều chỉnh với nội dung của bạn có thể có sự hiểu biết tốt hơn về chủ đề và tạo ra những phản hồi chất lượng cao hơn.
- Triển khai đơn giản hóa: Việc điều chỉnh mô hình yêu cầu ít công việc phát triển hơn của bạn, vì bạn có thể đơn giản sử dụng API GPT để tạo nội dung và thực hiện các phiên trò chuyện.
Nhược điểm:
- Lo ngại về quyền riêng tư dữ liệu: Gửi nội dung độc quyền của bạn đến OpenAI có thể làm lộ ra thông tin nhạy cảm hoặc mật, phụ thuộc vào tính chất của dữ liệu của bạn.
- Chi phí và thời gian: Việc điều chỉnh mô hình với OpenAI có thể tốn kém và mất thời gian hơn so với việc xây dựng cơ sở dữ liệu nhúng và triển khai cơ chế tìm kiếm.
- Cập nhật hạn chế: Cập nhật mô hình đã được điều chỉnh với nội dun
- g mới có thể đòi hỏi một vòng điều chỉnh tinh chỉnh khác, điều này có thể đắt đỏ và tốn thời gian.
- Hiện tại, GPT3.5 Turbo, mô hình cân bằng nhất (chi phí, hiệu suất, chất lượng), không cung cấp tùy chọn điều chỉnh tinh chỉnh.
2. Cân nhắc theo nội dung cụ thể
Khi lựa chọn giữa việc xây dựng một cơ sở dữ liệu nhúng và điều chỉnh mô hình với OpenAI, cũng quan trọng là xem xét kích thước, độ phức tạp và loại nội dung bạn đang có. Các tài liệu lớn có thể được hưởng lợi từ một cơ sở dữ liệu nhúng, vì bạn có thể tìm kiếm thông tin cụ thể và tạo ra phản hồi tập trung hơn. Ngược lại, việc điều chỉnh tinh chỉnh với OpenAI có thể phù hợp hơn cho các tài liệu nhỏ hơn hoặc đoạn thông tin, vì mô hình có thể học hiệu quả từ và sử dụng những mảnh thông tin nhỏ này. Độ phức tạp của nội dung cũng là một yếu tố: nội dung cực kỳ phức tạp có thể đòi hỏi điều chỉnh tinh chỉnh để đạt được kết quả tốt hơn, trong khi nội dung đơn giản hơn có thể hoạt động với cả hai phương pháp. Cuối cùng, loại nội dung có thể ảnh hưởng đến quyết định: dữ liệu có cấu trúc có thể phù hợp hơn cho một cơ sở dữ liệu nhúng, trong khi dữ liệu không có cấu trúc có thể hoạt động với cả hai phương pháp. Cân nhắc những yếu tố này, cùng với quyền riêng tư dữ liệu, ngân sách và độ phức tạp của triển khai, để xác định phương pháp phù hợp nhất cho dự án của bạn.
2.1 Kích thước của tài liệu
Tài liệu lớn:
- Nếu nội dung độc quyền của bạn bao gồm các tài liệu rất lớn, việc sử dụng một cơ sở dữ liệu nhúng có thể phù hợp hơn. Phương pháp này cho phép bạn tìm kiếm thông tin cụ thể trong những tài liệu này khi chạy và tạo ra phản hồi tập trung hơn.
- Việc điều chỉnh tinh chỉnh với OpenAI có thể không hiệu quả cho các tài liệu lớn, vì cửa sổ ngữ cảnh của mô hình bị hạn chế. Do đó, mô hình có thể không hiệu quả nắm bắt hoặc sử dụng hết thông tin từ các tài liệu phức tạp.
Tài liệu nhỏ:
- Nếu nội dung độc quyền của bạn bao gồm các tài liệu nhỏ hơn hoặc đoạn thông tin, việc điều chỉnh mô hình với OpenAI có thể phù hợp hơn, vì mô hình có thể học hiệu quả từ và sử dụng những mảnh thông tin nhỏ này.
- Cơ sở dữ liệu nhúng vẫn có thể được sử dụng với các tài liệu nhỏ, nhưng những lợi ích của việc điều chỉnh tinh chỉnh với OpenAI, như tích hợp và chất lượng tạo ra cải thiện, có thể quan trọng hơn trong trường hợp này.
Độ phức tạp của nội dung:
Nội dung phức tạp:
- Nếu nội dung của bạn rất phức tạp hoặc đòi hỏi sự hiểu biết sâu rộng về một lĩnh vực cụ thể, việc điều chỉnh mô hình với OpenAI có thể mang lại kết quả tốt hơn. Mô hình có thể được đào tạo để hiểu rõ ngữ cảnh và tạo ra các phản hồi chính xác hơn.
- Sử dụng một cơ sở dữ liệu nhúng cho nội dung phức tạp vẫn có thể khả thi nhưng có thể dẫn đến các phản hồi ít chặt chẽ hoặc không liên quan ngữ cảnh hơn.
Nội dung đơn giản:
- Nếu nội dung của bạn tương đối đơn giản hoặc chứa thông tin chung, cả hai phương pháp đều có thể hiệu quả. Sự lựa chọn sẽ phụ thuộc vào yêu cầu cụ thể của bạn, như quyền riêng tư dữ liệu, ngân sách và độ phức tạp của triển khai.
Loại nội dung:
Dữ liệu có cấu trúc:
- Nếu nội dung của bạn có cấu trúc, chẳng hạn như bảng biểu hay cơ sở dữ liệu, một cơ sở dữ liệu nhúng có thể là lựa chọn thích hợp hơn. Bạn có thể tìm kiếm và truy xuất thông tin từ dữ liệu có cấu trúc một cách hiệu quả, và mô hình GPT có thể không tự nhiên xuất sắc trong việc hiểu loại nội dung này.
Dữ liệu không có cấu trúc:
- Nếu nội dung của bạn không có cấu trúc, chẳng hạn như tài liệu văn bản hay bài viết, cả hai phương pháp đều có thể phát huy hiệu quả. Việc điều chỉnh mô hình với OpenAI có thể dẫn đến các phản hồi chặt chẽ và phù hợp với ngữ cảnh hơn, trong khi cơ sở dữ liệu nhúng cung cấp sự kiểm soát lớn hơn về dữ liệu và tính linh hoạt.
3. Kết luận
Sự lựa chọn giữa việc xây dựng một cơ sở dữ liệu vector (RAG) và điều chỉnh mô hình OpenAI (Fine-tune) sẽ phụ thuộc vào các đặc điểm của giải pháp như kiểm soát, linh hoạt, quyền riêng tư dữ liệu, ngân sách, và kích thước, độ phức tạp, và loại nội dung bạn đang có. Cân nhắc những yếu tố này, cùng với yêu cầu và ưu tiên cụ thể của bạn, để xác định phưcccc cccc cccc cccc cccc cccc cccc cccc cccc cccc ơng pháp phù hợp nhất cho dự án của bạn. Còn các phương pháp khác như xây dựng các điểm cuối API tùy chỉnh của riêng bạn với OpenAI hoặc thậm chí đào tạo một mô hình riêng trên cơ sở các mô hình ngôn ngữ lớn khác cũng có thể giải quyết những thách thức mà cả tìm kiếm nhúng và điều chỉnh tinh chỉnh không thể giải quyết được hiện nay, tuy nhiên, thường là đắt đỏ hơn nhiều. Tôi có thể viết một bài viết khác nếu có đủ sự quan tâm và khi có thời gian. Bạn có thể tham khảo giải pháp AI chatbot của MITIGA tại website https://aichatbot.com.vn. Chúng tôi sẽ tư vấn lựa chọn giải pháp và loại bỏ lỗi chính tả, phân đoạn và làm sạch dữ liệu, kiểm thử và tinh chỉnh trước khi đưa vào hoạt động.



0 Lời bình